-
[딥러닝 vision] NeRFDeep learning 2022. 9. 21. 10:12
'NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis' 2020년 ECCV
virtual object를 만들어 내는 방법
3D 물체를 보는 시점에 따라 물체를 잘 표현시켜주기 위한 방법
우리가 움직일 때마다 우리의 시점이 바뀌게 됩니다. 우리의 눈 혹은 카메라가 움직일 때마다 물체가 보이는 면이 달라지고 색도 달라기게 됩니다. 이를 잘 모델링하는 것이 어려운 문제인데 이를 하고자 시도한 것이 NERF이고 좋은 성능으로 최근 가장 핫한 모델입니다.
한 카메라 위치와 방향에서 물체가 있는 모든 pixel로 ( ex 1024x1024 pixel)로 ray를 쏩니다.
하나의 ray를 들여다보면 ray가 지나가는 곳에서 sample point 뽑고 이 입력으로하여 color 와 density를 출력으로 하는 MLP 있습니다.
이렇게 ray위의 sample point들의 color와 density가 구해지면, 각 sample point의 color 와 density를 이용해 이를 weighted sum 하여 그 pixel의 color를 구하게 됩니다.
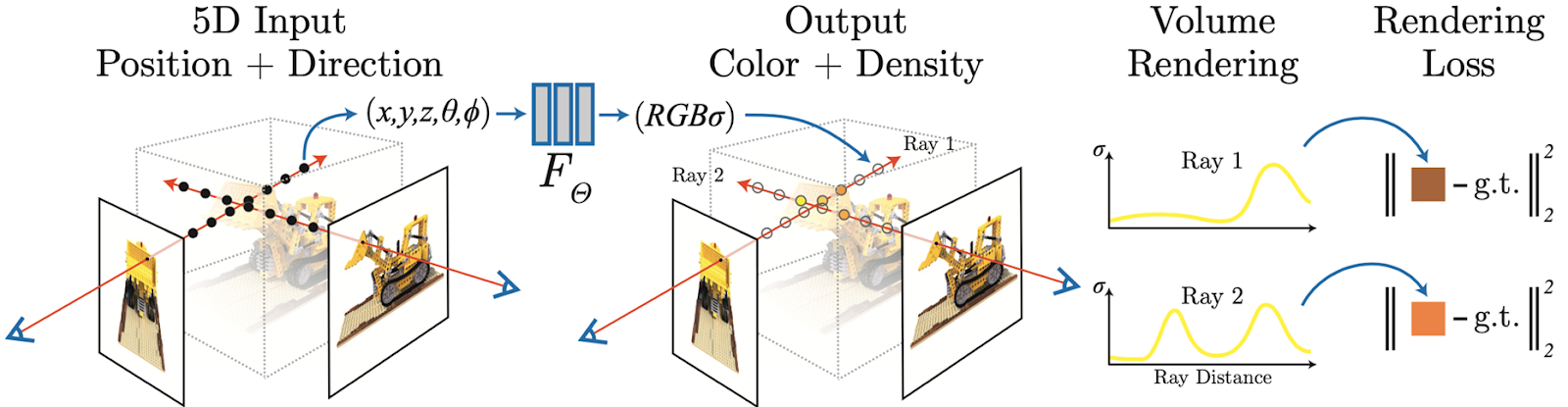
weighted sum에서 weight는 transmittance 와 opacity(probability of surface) 의 곱을 사용합니다. 앞의 sample point들에서 막고 있는 표면이 없을 확률과 내가 표면일 확률을 곱하여 ( 내 앞에 막고있는게 없고 내가 빛을 반사해서 색을 낼 수 있는 표면이라면 내 색이 가장 강하게 보일 것이므로 ) 이를 color의 weight로 사용하여 모든 sample point의 weighted sum으로 그 pixel의 color를 구하게 됩니다.
Plen Octree (ICCV 2021), Plenoxel (CVPR 2022)
NeRF는 시점이 바뀔 때마다 물체가 있는 모든 pixel에 ray를 쏘고 sample point를 뽑아서 MLP를 통과시키고, 이들을 weighted sum 하는 과정을 거쳐 그 시점에서 보이는 화면을 얻게됩니다. 이는 연산량이 너무 많이들어가기 때문에 real time으로 rendering 하기가 어렵습니다.
이를 극복하기 위해 NERF이후 다양한 연구들이 나왔는데 그 중 결이 비슷한 plenoctree와 plenoxel에 대해 가볍게 이해해보고자 합니다.
기본적인 아이디어는 뷰가 바뀔 때마다 매번 ray를 쏘고 sample point를 뽑고 MLP를 돌리지 말고, 기본적인 object의 색을 얻을 수 있는 값들을 ( object의 기본 보임 특성 ? ) voxel로 저장해놓아서 plenoctree로 만들어 놓고 이제 시점이 바뀔 때마다 sampling 해서 그 기본 값과 실제 값 차이를 보고 fine tuning 해서 사용함으로써 연산량을 줄이겠다는 아이디어 입니다.
plen octree는 각 voxel에 저장할 object의 기본적인 특징을 구할 때 NeRF와 유사하게 ray를 쏘고 ray에서 sample point를 구해서 MLP를 통해 density와 SH coefficient 값을 구하고 이를 voxel에 저장하고 fine tuning 하는 방식입니다.
Plenoxel은 이 과정을 하지 않아도 된다고 하는 연구입니다. 이렇게 각 voxel에 줄 초기 값을 MLP를 통해 구하지않고 그냥 random init에서 부터 시작해서 tuning 만 하더라도 성능이 잘 나온다는 연구로 간단하기 때문에 더 많이 활용될 것으로 생각됩니다.
'Deep learning' 카테고리의 다른 글