-
[딥러닝] continual learning ( incremental learning, lifelong learning ) : EWC, VCL, AGS-CL, GEM, A-GEM, ER, PNN, DEN, Piggyback, CPGDeep learning 2022. 9. 21. 15:12
continual learning, incremental learning, lifelong learning 은 기술적으로 목표가 같은 learning 방법들입니다. 단어 그대로 조금씩 차이는 있지만 같은 learning 방식이라고 이해해도 괜찮아 보입니다. 이들은 공통적으로 dataset 여러 개를 순차적으로 학습하는데 (sequential learning) 학습을 진행할수록 성능이 좋아지는 good forward tranfer와 학습이 진행되더라도 이전 dataset 을 기억하는 forgetting 방지를 목표로 합니다
meta learning이나 transfer learning 과 같은 다른 learning 기법들과 혼동된다면 아래 글을 참고하면 좋습니다
[딥러닝] continual learning ( incremental learning, lifelong learning ) vs transfer learning vs multi task learning vs meta l
우선 continual learning 에 대해 설명하기에 앞서 adaptive machine learning 이라는 큰 분야에서 사용되고 있는 learning 방법들의 이름이 많아 헷갈리지 않기 위해 이를 정리한다. - continual learning, incre..
u-b-h.tistory.com
continual learning 의 대표적인 방법들에 대해 보기 전에 continual learning 이 어디에 사용되는지 알아보겠습니다.
대부분 딥러닝은 학습 데이터가 모두 준비되어 있는 상태였고, 학습 데이터를 overfitting 되지 않게 잘 학습하고, generalization 잘 시키는 것이 목표입니다. 하지만 실제 딥러닝을 사용하게 될 때, 데이터가 현재 시점에 모두 준비되지 않을 수 있고, 앞으로 데이터가 계속 추가될 수 있는 경우가 있습니다. 이렇게 이전까지의 데이터로 학습된 모델에 추가 데이터를 학습할 때 이전 데이터의 학습 내용을 잊지 않으면서도, 추가된 데이터도 잘 맞추도록 학습 시키는 방법이 continual learning입니다. 데이터가 추가되면서 class가 추가될 수도 있으며, 새로운 task가 생길 수 도 있습니다
continual learning은 forward transfer이 잘되야하고(plastic 하다고도 함), 새로운 데이터로 학습할 때, 이전 학습 내용에 대한 forgetting을 방지해야 하는 것이 주요 문제입니다.
이 두 문제는 서로 trade off 관계가 있어서 두 문제를 적절히 해결하기 위한 연구들이 진행되고 있습니다. 이를 위한 접근법은 크게 Regularization-based, Memory Replay-based, Parameter Isolation-based 으로 나눌 수 있습니다.
우선 continual learning의 주요 문제인 plasticity-stability delemma에 대해 알아보겠습니다.
plasticity-stability dilemma
Plasticity는 good forward transfer 입니다. 즉 forward transfer가 잘되는 것을 plastic 하다고 합니다. neural network는 기본적으로 plastic 합니다. (학습을 더 할수록 일정 수치까지는 성능이 증가하기 때문에) 새로운 task나 data가 들어왔을 때, 이를 학습해야나가야하기 때문에 필요한 성질입니다.Stability는 Catastrophic forgetting을 극복하는 성질입니다. 예를 들어 새로운 dataset이나 새로운 task data가 들어올 때, 이전 task data들은 없을 수 있습니다. 이전 dataset로 부터 배운 내용은 그 때 학습하고나서 이후 다른 dataset 혹은 task에 대해 학습할 때 이를 잊으면 안됩니다.하지만 딱 생각하기에도 plasticity와 stability는 상충되는 특징입니다. 새로운 내용을 잘 배우려면 이전 내용이 날아갈 것이고, 이전 내용을 잘 기억하기 위해서 새로운 내용을 잘 배우지 못할 수 있습니다. 이 두 가지를 잘 해내고자 하는 것이 continual learning의 핵심입니다.
이 두 가지 성질만 만족하는 것이 아니라,
- 여러 task 혹은 여러 dataset가 들어와야 하므로 scalable 해야하며,
- 이전 task와 관계가 있는 새로운 task를 학습했을 때, 이전 taks 를 까먹지 않을 뿐 아니라 새로운 task 학습을 함으로써 이전 task까지 더 잘 풀리도록 학습하는 것을 positive backward transfer라 하며, continual learning 에 필요한 것 입니다.
- 마지막으로 task boundary가 주어지지 않더라도 continual learning이 되어야 합니다.
대표적인 continual learning 접근 방식에는 3가지가 있으며, 간략한 내용은 아래와 같습니다.
- regularization : 각 task 마다 중요한 weight에는 regularization을 쎄게 줘서 weight update가 크게 안일어나 유지되도록 하는 방법입니다.
- parameter isolation : 새로운 task 마다 network를 확장시키는 방법입니다.
- memory replay : 이전 task data를 기억해두었다가 새로운 task가 들어왔을 때 이전 task data를 같이 사용하는 방법입니다.
이제 각 접근 방식에 대해 알아보려고 합니다.
regularization-based continual learning
이전 task를 학습할 때 주요한 weight를 찾아내서 중요한 node, weight에 high regularization strength를 줘서 주요 node, weight들은 유지(많이 update하지 않음) 하면서 다음 task를 학습해나가는 방법입니다. 위에서 얘기했던 특징들중 stability에 초점을 맞춘 방법으로 볼 수 있습니다.Elastic Weight Consolidation (EWC)
 update 시 이전 task의 low error 범위를 벗어나지 않도록 penalty를 주면서 update 하는 idea로 weight의 중요도를 Fisher Information Matrix(FIM)으로 판단하게 된다. FIM 평균이 클수록 중요한 weight이므로 regularization을 세게 한다. FIM은 각 weight의 gradient의 제곱으로 구한다.정리하면, gradient가 크다 == 결과값에 영향을 많이 준다 == 중요한 parameter이다 -> penalty(regularization)를 많이줘서 많이 움직이지 않도록 한다.
update 시 이전 task의 low error 범위를 벗어나지 않도록 penalty를 주면서 update 하는 idea로 weight의 중요도를 Fisher Information Matrix(FIM)으로 판단하게 된다. FIM 평균이 클수록 중요한 weight이므로 regularization을 세게 한다. FIM은 각 weight의 gradient의 제곱으로 구한다.정리하면, gradient가 크다 == 결과값에 영향을 많이 준다 == 중요한 parameter이다 -> penalty(regularization)를 많이줘서 많이 움직이지 않도록 한다.단점은 forgetting은 해결했으나 forward transfer가 좋지는 않다. 또한 penalty를 각 parameter 마다 구해야하기 떄문에 parameter 수 만큼의 penalty를 저장하는 공간이 필요하다.
Variational Continual Learning(VCL)
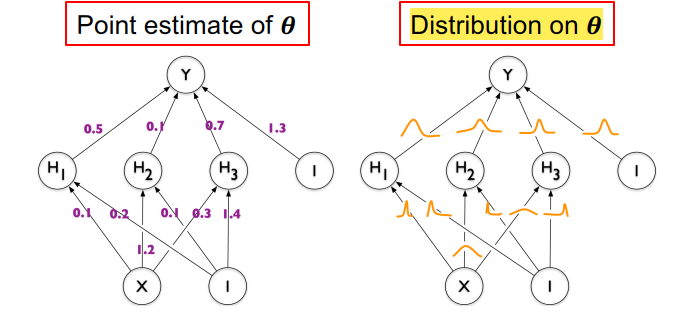
EWC가 FIM으로 중요도를 구했다면, VCL은 중요도 parameter 시그마를 학습하는 방법이다.
각 parameter들의 분포를 추정하고, 시그마(uncertainty, 중요도) 를 얻어서 이를 통해 regularization 하는 것으로 볼 수 있다.
요약하면, "t-1 task까지의 시그마가 작다 == mean 중심으로 분포가 몰려있다 = certrain 하다 == variance 작다 == 중요한 parameter 이다 == regularization 세게한다" 이다
Adaptive Group Sparsity based Continual Learning(AGS-CL)
 EWC와 VCL은 weight-level regularization 방법을 사용했다. AGS-CL은 node-level regularization과 중요한 parameter은 아예 update 하지 않고 고정시키는 방법을 제안한다. 이 때 regularization 을 위한 값이 group sparse norm이고, update 방식을 proximal gradient descent 라 한다.node 를 중요 group과 중요하지않은 group으로 나누어서 중요 group은 update를 시키지 않고, 중요하지 않은 group은 아예 weight 들을 0으로 만들어서 pruning 하거나 다시 init 한 후 다음 step에서 새로 학습을 시작하는 방식을 사용한다.이 때, node의 중요도는 간단하게 activation function인 ReLU에서 activation된 값들의 평균을 사용한다 activation이 많이된 것이 중요한 node로 보는 것이다.
EWC와 VCL은 weight-level regularization 방법을 사용했다. AGS-CL은 node-level regularization과 중요한 parameter은 아예 update 하지 않고 고정시키는 방법을 제안한다. 이 때 regularization 을 위한 값이 group sparse norm이고, update 방식을 proximal gradient descent 라 한다.node 를 중요 group과 중요하지않은 group으로 나누어서 중요 group은 update를 시키지 않고, 중요하지 않은 group은 아예 weight 들을 0으로 만들어서 pruning 하거나 다시 init 한 후 다음 step에서 새로 학습을 시작하는 방식을 사용한다.이 때, node의 중요도는 간단하게 activation function인 ReLU에서 activation된 값들의 평균을 사용한다 activation이 많이된 것이 중요한 node로 보는 것이다.Memory replay-based continual learning

Regularization-based 방식들은 parameter나 node의 중요도를 구하고, 중요한 애들은 update 할 때 regularization을 많이 준다는 것이 기본원리이다. 즉 이전 step 까지의 중요도를 구해오면서 이번 step의 update를 하는 것인데, Memory replay-based 방식은 중요도를 구하지 않고 이전 task들의 data를 저장해두었다가 현재 task update에 사용한다는 idea이다.
regularization based 방식은 이전 task들의 data를 안본다고하지만, 결국에는 이전 task로부터 얻어진 중요도를 다음 task에서 사용하기 위해 이 데이터를 저장한다. 이렇게 데이터를 저장할거면 중요도를 저장하는게 아니라 이전 task의 데이터 일부를 저장해보자는 방법이다.
Gradient episodic memory(GEM)
NeurIPS 2017
task 마다 sample 몇 개를 저장해 episodic memory 를 구성함.
만약 총 task 수를 미리 알고 있다면 (total memory budget / total number of tasks) 만큼의 sample을 저장하고, 총 task 수를 모른다면 m 을 memory에 맞게 줄여나간다.
idea는 이전 task까지 학습된 모델보다 이전 데이터들을 잘하거나 같게 하도록 update 하자 입니다.

하지만 위와 같이 loss를 계산하는 것은 어려움이 있기 때문에 아래와 같이 gradient 를 사용한다. 아래 식의 뜻은 이전 data로 구한 gradient와 현재 data로 구한 gradient의 각도가 90도 이상 벌어지지 않게 같은 방향으로 학습을 진행시킨다는 의미로 결국 현재 task data와 과거 task들의 data에 대한 loss 둘 다 줄이겠다는 의미가 된다.


Averaged GEM(A-GEM)
GEM은 이전 task들의 data와 현재 data에 대한 gradient를 계산하고, 이 각도가 90도 이하가되도록 조정하는 등 계산 비용이 높으며 이전 task들의 data 저장하는 공간도 많이 필요하다. 이를 보완한 것이 A-GEM이다.

위 그림과 같이 GEM은 모든 이전 task들의 gradient를 구하고 최대 90도 이상 넘어가지 않도록 gradient를 잡아주는 방법인데, A-GEM은 이를 단순화하여 이전 task들까지의 평균 gradient만을 기억하고 평균 gradient와 90도가 넘어가지 않도록 gradient를 잡아주는 방법이다. 아주 단순하지만 효과가 좋았다.
Experience replay(ER)
ICLR 2019
GEM, A-GEM은 이전 데이터를 gradient 방향을 조정해주는데만 사용하고, 직접 학습에 사용하지는 않았다. ER은 쌓아둔 이전 데이터를 직접 학습에 사용하는 방법이다.ER은 mini-batch를 구성할 때 현재 task의 data에서 반, 이전 task들의 data에서 반 가져와 이 mini-batch로 gradient 를 구해 update 한다. 이 때 GEM, A-GEM 같이 gradient 방향을 제한하지 않고 단순히 mini-batch에 이전 task data를 섞는 방법이다.
이렇게 data를 섞어서 gradient를 구하면 결국 GEM, A-GEM에서 한 것 처럼 이전 data들의 gradient와 현재 data의 gradient 사이의 적절한 gradient가 구해질 것이다라는 idea이며 효과를 보였다.
Regularization과 replay memory 방식의 장단점을 정리해보면 아래와 같다.
Regularization-based
- 장점 : task들의 training data 저장하지 않기 때문에 privacy issue가 없음. 다른 방법과 결합 가능.
- 단점 : replay-memory 방식에 비해 비교적 성능 안좋음
replay memory-based
- 장점 : 간단하면서도 성능 좋음
- 단점 : data를 직접 저장하므로 privacy issue가 있어 쓰지 못하는 경우도 있음
위 두 방법은 모두 model의 크기는 고정시켜놓고 고정된 model을 어떻게 잘 update해 나갈 것인지에 대한 방법이였다.
뒤에 나올 parameter isolation과 dynamic architecture는 모델의 capacity를 바꾸는 방식이다.
Parameter isolation / Dynamic architecture
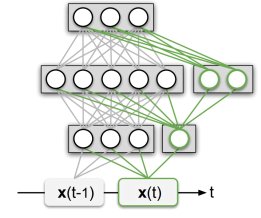 task가 들어옴에 따라 model에 추가로 parameter를 넣고, task 마다 사용하는 parameter를 분리하기도 하고, 나눠 update 하는 방식이다. 실제 활용 하기에 hyperparameter도 많아 간단하게 설명하였다.Progressive Neural Network ( PNN )
task가 들어옴에 따라 model에 추가로 parameter를 넣고, task 마다 사용하는 parameter를 분리하기도 하고, 나눠 update 하는 방식이다. 실제 활용 하기에 hyperparameter도 많아 간단하게 설명하였다.Progressive Neural Network ( PNN ) task 가 늘어날 때마다 위 그림에서 column 한 줄을 모델에 추가하는 방식이다. 이전 column들은 새로운 task data로 학습하지 않고 고정시킨다. 다만 새로운 column을 현재 task 데이터로 학습 시 이전 task들에서 생성된 column들에서도 vector를 받아오는 구조이다.Dynamically Expandable Networks(DEN)
task 가 늘어날 때마다 위 그림에서 column 한 줄을 모델에 추가하는 방식이다. 이전 column들은 새로운 task data로 학습하지 않고 고정시킨다. 다만 새로운 column을 현재 task 데이터로 학습 시 이전 task들에서 생성된 column들에서도 vector를 받아오는 구조이다.Dynamically Expandable Networks(DEN)PNN은 task에 따라 linear 하게 모델 크기를 늘린다 ( column 하나 )
DEN은 dynamic 하게 모델을 늘리고, 이번 task에 사용할 이전 network를 선택하는 방식이다.
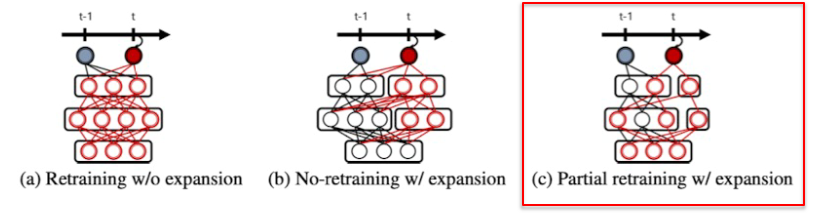 DEN 알고리즘은 아래와 같이 동작한다1. 새로운 task를 학습할 때 retrain할 parameter를 선택한다2. 새로운 task에 대해 학습할 때 loss가 많이 줄어들지 않으면 network가 충분히 크지 않은 것으로 판단하고 network 크기를 키운다.3. 이전 task에서 학습한 neuron 과 유사도가 비슷한게 있으면 split & duplicate 한다.Piggybackpre-trained model은 fix해 놓고 task에 맞는 binary mask를 학습해서 필요없는 부분은 masking 하고 pre-trained model을 가져다가 task에 맞게 학습하는 방법이다.Compacting, Picking and Growing (CPG)
DEN 알고리즘은 아래와 같이 동작한다1. 새로운 task를 학습할 때 retrain할 parameter를 선택한다2. 새로운 task에 대해 학습할 때 loss가 많이 줄어들지 않으면 network가 충분히 크지 않은 것으로 판단하고 network 크기를 키운다.3. 이전 task에서 학습한 neuron 과 유사도가 비슷한게 있으면 split & duplicate 한다.Piggybackpre-trained model은 fix해 놓고 task에 맞는 binary mask를 학습해서 필요없는 부분은 masking 하고 pre-trained model을 가져다가 task에 맞게 학습하는 방법이다.Compacting, Picking and Growing (CPG)모델을 필요한 부분만 압축하고 이를 고정시키고, 이 중 새로운 task에 사용할 parameter를 골라내고, 새로운 task에 대해서 학습할 parameter가 부족하다면 parameter를 추가로 넣는 방법이다.
Compacting은 pruning 하고 retrain하는 것이고, compacting이 끝나면 weight 들은 frozen 된다.
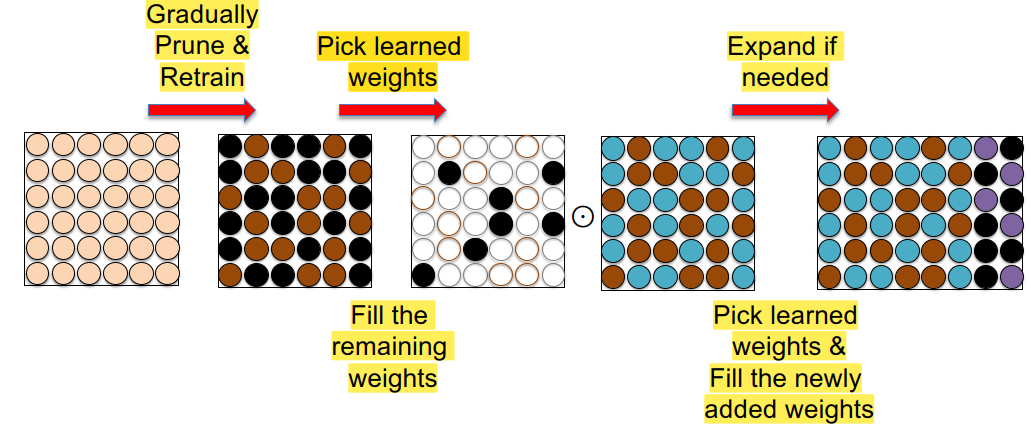
그 뒤에 다음 task 학습 시에는 frozen된 parameter 를 제외하고 새로운 task에 사용될 parameter를 선택하고 학습 및 compacting 한다. 만약 새로운 task에 사용될 parameter가 부족하다면 parameter를 늘려준다.
'Deep learning' 카테고리의 다른 글
[딥러닝] imbalanced data 학습 (0) 2022.09.21 [딥러닝 vision] NeRF (1) 2022.09.21 [딥러닝 경량화] 모델, 네트워크 경량화 : Quantization - PTQ, QAT (0) 2022.09.03 [딥러닝] Graph Neural Networks(GNN) 2 - GNN : GCN, subgraph embedding, graph attention network(GAT), HAN, GTN (0) 2022.08.11 [딥러닝] Graph Neural Networks(GNN) 1 - Node embedding : background ~ random walk ~ deepwalk ~ node2vec (0) 2022.08.10